
Im Bereich des maschinellen Lernens gilt seit vielen Jahren das Mantra: Mehr Daten bedeuten bessere Ergebnisse! Bislang traf dies auch in den meisten Fällen zu. Datensätze sind von einigen Tausend Datenpunkten zu Milliarden und Abermilliarden angewachsen, mit der Tendenz, noch größer zu werden.
Immer mehr Daten bringen jedoch auch eine Reihe von Herausforderungen mit sich: Die Trainingszeit erhöht sich, die Datenerfassung kann mühsam und teuer sein, vor allem in sehr spezifischen Bereichen. Jedoch sind Daten komplex und nicht alle sind gleich. Es kann zu Redundanzen oder Qualitätsproblemen kommen, die bei der Sammlung großer Datenmengen weiter zunehmen.
Es stellt sich die Frage: Muss es immer mehr sein? Oder könnten bessere Daten die Leistung genauso gut verbessern wir mehr Daten? In diesem Artikel wird beleuchtet, wie mehr Daten und Daten höherer Qualität die Leistung eines maschinellen Lernsystems beeinflussen.
Um dies zu beurteilen, werden Experimente mit dem KITTI-Datensatz und RetinaNet durchgeführt, einem Bounding-Box-Detektor zur Ermittlung von Datenqualität. Im Szenario gibt es zwei Variablen: Datenqualität und Datensatzgröße. Für den Aspekt der Datenqualität werden die Beschriftungen des Datensatzes nach dem Zufallsprinzip in unterschiedlichem Ausmaß beschädigt, z. B. haben 5 % Probleme mit der Größe der Bounding Box. Die fehlerhaften Daten werden genutzt und das neuronale Netz mit verschiedenen Anteilen des gesamten Datensatzes (25 % bis 100 %) trainiert.
Als Bewertungskriterium wird der mAP-Wert verwendet. mAP steht für mean Average Precision und ist eine beliebte Metrik in der Objekterkennung. Wie der Name sagt, handelt es sich um den Mittelwert der durchschnittlichen Präzision (AP) jeder Objektklasse. Die durchschnittliche Präzision ist die Fläche unter der Precision-Recall-Kurve eines Objektdetektors für eine Klasse.
Dies wird für 10 zufällige Seeds durchgeführt und führt zu folgenden Ergebnissen:
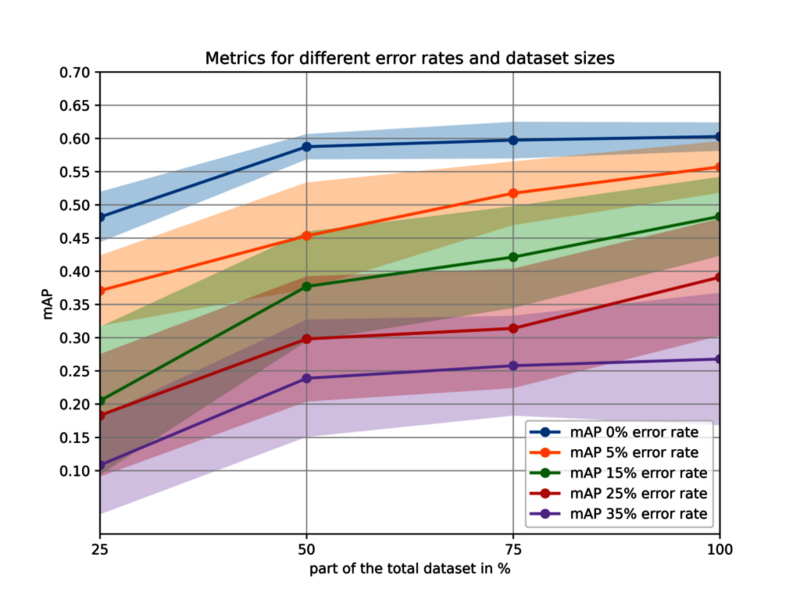
Es ist deutlich zu erkennen, dass die beste Leistung nur erreicht werden kann, wenn die Datenqualität ausreichend hoch ist. Außerdem scheint die positive Wirkung zusätzlicher Daten geringer zu werden, insbesondere bei Daten mit einer hohen (0 %) oder sehr niedrigen (35 %) Qualitätsstufe. Dies wird deutlicher, wenn man die mAP-Verbesserung bei jeder Vergrößerung des Datensatzes betrachtet:
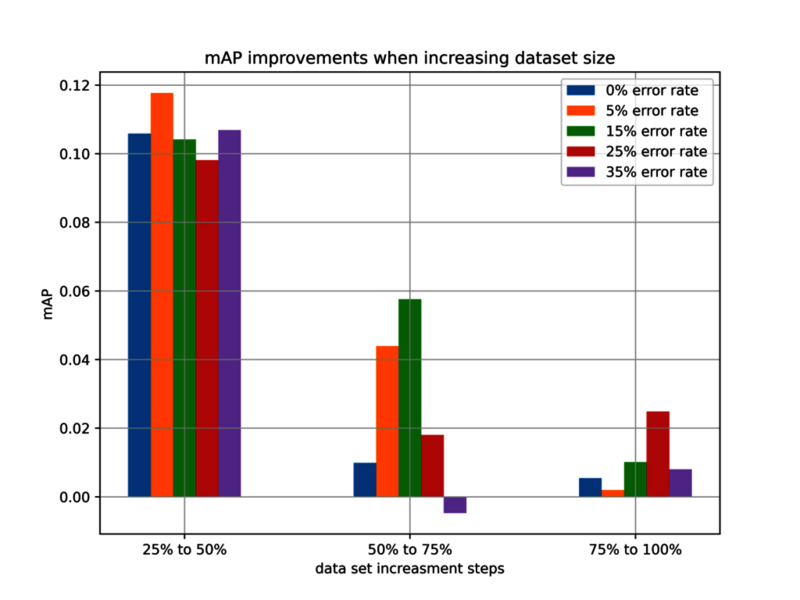
Mit jedem Schritt wird der Leistungsgewinn durch mehr Daten geringer. Ein anderes Verhalten ist bei steigender Datenqualität zu beobachten. Nachfolgend wird die durchschnittliche Verbesserung für jede Verringerung der Fehlerquote angegeben:
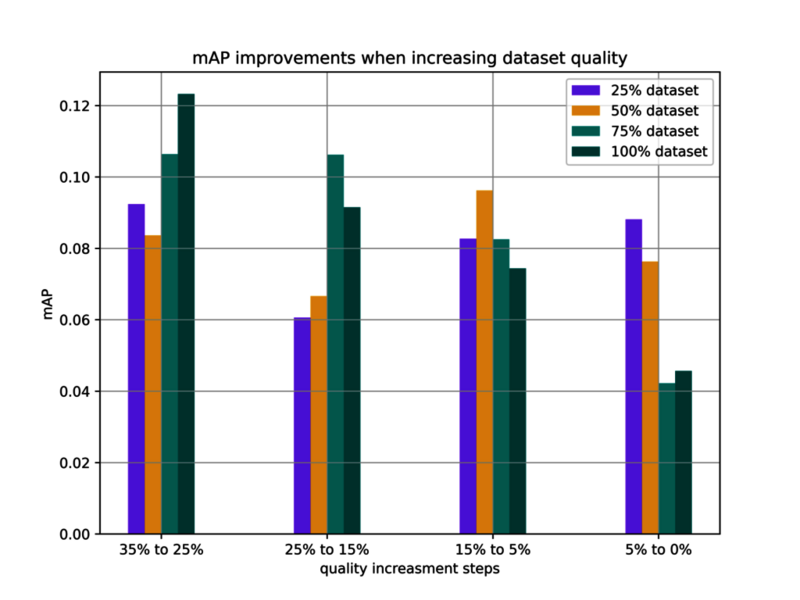
Hier ist eine konsistentere Verbesserung für jeden Schritt über alle Qualitätsstufen sowie die Größe eines Datensatzes hinweg zu beobachten. Allerdings wird sie auch geringer, wenn eine hohe Qualitätsstufe erreicht wird.
Die Ergebnisse hier zeigen, dass mehr Daten nicht der einzige Weg sind, um eine bessere Modellleistung zu erreichen.
Für sicherheitskritische Anwendungen wie im ADAS/AD-Bereich ist es unerlässlich, ist eine Qualitätssicherung durchzuführen. Nicht die Quantität, sondern die geforderte Datenqualität muss gewährleistet werden, um aufkommende Probleme in der ADAS-Funktionsentwicklung zu analysieren und zu lösen.
Eine Verbesserung der Datenqualität durch die Behebung von Kennzeichnungsproblemen kann sich ebenso oder sogar noch stärker positiv auswirken. Dies kann nützlich sein, wenn die Daten selten oder schwer zu beschaffen sind. Außerdem kann die beste Leistung nicht mit schlechten oder falschen Bezeichnungen erreicht werden.
Sicherlich zeigt dies nur einen Anwendungsfall und die Ergebnisse variieren je nach Bereich, Datenmenge und Modell. Nichtsdestotrotz stimmen die Ergebnisse mit unseren Erfahrungen aus der Zusammenarbeit mit Kunden aus verschiedenen Branchen überein.
Wenn Sie sich für das Thema interessieren oder mehr über die Qualität Ihrer Daten wissen wollen, nehmen Sie einfach Kontakt mit uns auf.